[CS] CS50 / 학습 노트

edwith <CS50> 수강한 학습 노트
CS50 : 하버드 대학에서 진행하는 컴퓨터과학 기초 교양 과목
1. 컴퓨터와 컴퓨팅
- FSB(프론트 사이드 버스) : 기억장치의 속도나 컴퓨터 안 메인보드 부품들 속도를 볼 때 참고할 수 있음.
- 하드웨어 : 컴퓨터를 물리적으로 구성하는 요소. 컴퓨터에 연결돼 추가적인 기능을 수행함.
1. 입출력장치
1-1. 입력장치 : 사용자가 입력한 자료를 컴퓨터가 이해할 수 있는 형태로 변환하는 장치
- 마우스, 키보드, 스캐너
1-2. 출력장치
- 모니터 : 크기는 보통 대각선 끝과 끝의 길이를 인치로 표시. 해상도는 우리가 이미지를 볼 때 얼마나 선명하게 볼 수 있는 가를 숫자로 나타냄. 픽셀의 개수가 많으면 많을수록 해상도는 높아지고 선명한 이미지를 볼 수 있음.
- 프린트
2. 기억장치 : 입력된 명령이나 데이터가 저장되는 공간.
2-1. 주기억장치
- RAM : 데이터를 일시적으로 저장하는데 사용되는 임의 접근 기억장치. 즉, 휘발성이 있음. 파일이나 프로그램을 더블클릭하면 도착하는 곳. RAM이 메모리에 얼마나 많은 양의 정보를 저장할 수 있는지 측정하는 단위는 보통 기가바이트(GB) 사용. HDD보다 훨씬 빠름. 크기가 클수록 여러 가지 프로그램을 HDD가 아닌 RAM에 바로 넣을 수 있기에 유용함. (크기가 작은 경우, A프로그램보다 B프로그램을 우선시 하려면 A이 RAM에서 빠져나와 HDD로 옮겨가야 하고 HDD에 있던 B가 RAM으로 옮겨짐. 이 과정에서는 가상기억장치가 사용됨. 근데 RAM의 크기가 크면 A가 RAM에 있는 상태에서 B를 RAM으로 바로 옮길 수 있음.)
2-2. 보조기억장치
- 하드드라이브(C:) : 영구적으로 데이터 저장. 휘발성 없음. ex) 하드디스크(Hard Disk Drive, HDD)는 원판 모양의 플래터를 회전시켜 드라이브에 데이터를 읽고 쓰는 원리
- SSD(Solid State Drive) : 움직이는 부품 없이 더 빠른 속도로 데이터를 읽고 쓰는 대신 가격은 더 비쌈.
- 플래시 드라이브(=USB 메모리 스틱) : 그 자체에 하드드라이브가 있지는 않지만 작은 크기의 '플래시 기억장치'. 컴퓨터에 USB 포트를 꽂는 장치가 있고 여기에 꽂음. 이동식 저장공간 기기로 SSD와 마찬가지로 움직이는 부품이 없음. 전기 신호로 자료를 저장함.
- '광학 디스크 드라이브 : 컴퓨터가 CD나 DVD를 읽고 쓸 수 있도록 함.
- 가상기억장치 : 주기억장치처럼 사용할 수 있는 보조기억장치의 일부분.
3. CPU(Central Processing Unit, 중앙처리장치, 프로세서) : 입력장치에서 받은 명령을 실제로 처리함. 1초에 얼마나 많은 연산을 할 수 있는지 속도를 측정하는 단위는 기가헤르츠(GHz). 한 번에 64bit 정도만 처리하면 되기 때문에 약 1MB 정도의 저장공간만 있음. 컴퓨터는 아주 빠르고 인간은 느리기에 컴퓨터가 동시에 많은 일들을 처리하고 있다는 생각은 착각임. 즉, CPU는 보통 한 번에 한 가지 일만 처리함.
- L1캐시, L2캐시는 CPU에 아예 붙어서 나옴. 이 두 캐시도 숫자가 클수록 좋음. 그래서 더 느릴 것 같은 1.3GHz 컴퓨터가 1.5GHz 컴퓨터보다 빠를 수 있음. (혹은 후자보다 전자의 컴퓨터가 RAM 용량이 크든가!)
- CPU캐시메모리(L1, L2, L3캐시)는 RAM보다 더 빠르게 정보를 읽고 쓰지만 기억장치 용량이 더 작음. L1이 가장 작고 빠르며, 중앙처리장치가 재빨리 받아서 처리할 수 있도록 몇 KB의 데이터만 저장함. L2는 L1보다 조금 크지만 그만큼 느림. L3은 보통 몇 MB를 저장할 수 있어서 셋 중 가장 크지만 가장 느림. 그래도 RAM보다 빠름.
4. 주변기기 : 컴퓨터 자체부품이 아닌 경우 보통 컴퓨터와 연결해서 사용. 컴퓨터에 있는 물리적 포트에 꽂혀 컴퓨터에 연결됨. 많이 알려진 포트로는 범용 직렬 버스(USB) 포트가 있음. 1990년대 개발된 USB 포트는 업계 표준으로 대부분의 컴퓨터 주변기기들은 모두 USB 연결을 지원.
- 키보드, 외장 스피커.
- 비트(bit) : 정보량을 나타내는 최소 기본 단위. 이진법의 최소 단위. 1 bit는 0, 1을 표현하는 이진수 1자리. 이진 숫자(binary digit)라는 뜻.
- 메시지 정보량 : 사건의 수(number)뿐만 아니라 그것이 일어나는 확률(probability)도 영향 받음.
- 컴퓨터는 저장돼있는 데이터를 수정하기 위해 비트에 수학적 연산 수행 가능.
- 비트열 : 1(ON, TRUE), 0(OFF, FALSE)
- 8 bit로 나타낼 수 있는 가장 큰 숫자 : 255.
- 바이트(byte) : 8 bit. 알파벳 한 글자.
- 1KB(kilobyte) = 1,024 byte. (2^10)
- 1MB(megabyte) = 1,000,000 byte. (= 100만 byte) 1분 길이의 MP3 노래.
- 1GB(gigabyte) = 10억 byte. 30분 길이의 HD영화.
- 1TB(terabyte) = 1조 byte. (1000GB) '심슨네 가족' 열여섯 시즌.
- 페타바이트, 엑사바이트.
- 2진수(binary) : 0과 1로 이루어짐. 컴퓨터는 2진수로 소통함. 2진법은 컴퓨터가 이해할 수 있는 언어체계지만, 많은 정보를 처리하는 컴퓨터에는 비효율적일 수 있음.
- 10진수(decimal) : 인간이 주로 사용함. 0부터 9까지의 숫자 10개.
- 16진수(hexadecimal) : 이진법 외에도 디지털 데이터의 또 다른 표현 방법. 프로그래머들이 숫자를 표현하고 싶을 때 주로 사용. (0~9 + a~f). 4bit 패턴과 완벽히 대응해서 2진수를 간단하게 표현하는 데에 유용함. 10진수보다 16진수가 2진수를 간단하게 표현 가능하다는 의미.
※ JPG 이미지 파일은 항상 255 216 255로 시작되고 이것은 10진수. 이걸 바꾸면 16진수가 2진수보다 10진수를 훨씬 간단히 표현함.

- ASCII코드 : 알파벳 글자를 10진수에 대응한 표. 아스키코드를 사용하면 글자를 비트 패턴으로 쉽게 변환 가능. (글자->10진수->2진수) 즉, 아스키는 문자를 컴퓨터가 이해할 수 있는 이진 데이터(0, 1)로, 혹은 그 반대로 변환하는 표준 코드체계.
- 기본 ASCII코드 : 7비트만 이용. 2^7=128개의 문자 가능.
- 확장 ASCII코드 : 8번째 비트를 추가해서 2^8=256개의 문자 가능.

- 유니코드(Unicode) : 100만 개 이상의 문자를 나타낼 수 있는 문자 인코딩 표준. 첫 128개의 문자는 ASCII코드의 128개 문자와 동일해서 서로 호환 가능.
- 컴퓨터는 파일의 초반 비트를 보고 이미지 형식이면 그래픽으로 보여주고, Word 형식이면 문서로 보여줌.
- 이미지 : 그래픽 파일 형식. 저장되는 형식에 따라 파일 안에 들어가있는 비트 데이터들의 구조가 다름. 보통 첫 부분에 파일을 구분할 수 있는 구분자를 넣어둠.
- JPEG : 첫 부분이 255 216 255라는 10진수로 시작되는 게 구분자. 이미지를 압축하는 장점. 1600만색을 표시할 수 있어서 고해상도를 나타내기에 적합함.
- BMP : 픽셀이라는 점들의 패턴. 내부적으로 파일의 헤더(처음 몇몇 바이트)가 3 byte 이상으로 이루어짐. 마이크로소프트가 만든 파일 형식. 이미지데이터를 가장 단순하게 저장하지만 압축을 하지 않으므로 파일크기가 큼.
- GIF : 256색을 표시함. 이미지의 전송을 빠르게 하기 위한 압축저장 방식 사용. JPEG보다 압축률은 낮지만 압축 시 이미지의 손상이 적음.
- PNG : GIF와 JPEG의 장점을 합쳐 놓은 압축 방식. GIF보다 압축률이 좋고 JEPG보다 원본에 손상이 적어 효과적.

- 가상현실(VR, Virtual Reality) : 3차원 세계에서 게임이나 비디오 등의 시뮬레이션 경험 가능. 가상의 환경이나 상황을 컴퓨터로 만들어서 사람들이 실제로 그 상황에 들어와있는 것처럼 느끼고 상호작용할 수 있도록 만들어주는 인터페이스.
- 원리 1 : 우리의 양 눈은 각각 보는 각도가 달라서 양안시차 발생. 양안시차로 원근감을 느끼고 물체를 입체적으로 인식 가능한 것. vr기기의 양 렌즈는 사람의 양안시차만큼 다른 각도로 촬영된 영상이 재생돼서 일반 디스플레이와 달리 입체감이 느껴짐.
- 원리 2 : 사람이 바라보는 방향에 따라 영상을 바꾸기 위해 '모션 트래킹 센서' 사용. 머리에 씌워진 기기 안에 가로, 세로, 높이를 측정하는 센서가 있음.
- 증강현실(AR, Augmented Reality) : 사용자에게 기존의 주변환경과 분리된 전혀 다른 환경을 경험하게 하지 않고, 현재의 환경 위에 영상이나 게임 등의 효과를 입히는 기술
- 원리 1 : 스마트폰처럼 카메라와 디스플레이가 함께 있는 기기 필요.
- 원리 2 : vr과 마찬가지로 위치와 기울기를 측정하는 센서 필요.
- 인공지능
- 음성 인식 : 대답보다 질문을 이해하는 인공지능에 더 초점 둘 것. 마이크 같은 소리 센서를 통해 입력된 음향 신호를 단어나 문장 등으로 변환하는 기술. ex) Siri, Cortana, Echo, 빅스비 등
- 대부분 (어떤 것이 이 소리를 만들었는지를 확률적으로 정하는) 확률 모델을 가짐. 아래 3가지.
- 음성 모델 : 은닉 마르코프 모델이라는 계산 기술에 기반. 시간, 주파수 등의 특징 면에서 발음을 구분함.
- 발음 모델
- 언어 모델 : 세 모델 중 가장 복잡해보일 수 있지만 n-gram 모델을 사용해서 실제로는 가장 간단함. 통계적으로 뒤의 단어가 앞 단어의 뒤에 올 확률을 계산함.
- 자연어 처리 : 컴퓨터가 인간의 일상 언어를 이해하도록 함. 문장 전체보다는 구와 절로 나누어 사용된 단어의 조합으로 의미를 파악하는 것도 자연어 처리의 일부. 컴퓨터가 사람의 언어를 기계적으로 분석하여 컴퓨터가 이해할 수 있는 형태로 바꾸어 처리하는 것.
- ELIZA(1966) : 조셉이 만든 소프트웨어 시스템. 심리치료사와의 대화를 모방하도록 디자인 됨. 인간과의 대화를 실질적으로 이해하기보다 입력 받은 문장을 특정 방법으로 내용을 바꾼 뒤 비슷하게 대답하는 '패턴 매칭' 방식.
- 세 가지 모델로 구성된 음성인식을 통해 단어를 알아들은 뒤에는 문장구조 분석(Syntactic Processing), 의미 처리(Semantic Processing), 인지모델(Pragmatic Processing)을 함. 그럼 인공지능은 인간과 문맥에 맞는 대화를 얼추 할 수 있음. ex) IBM의 Watson
- 문장구조 분석(Syntactic Processing) : 문장을 도표화. 명사, 대명사, 동사 등을 구분.
- 의미 처리(Semantic Processing) : 각 단어가 어떤 의미를 담고 있는지 확인. ex) '존'이라는 단어를 이름으로 구분
- 인지모델(Pragmatic Processing) : 문맥 파악.
- 나중에는 인공지능과 '비언어적 소통'도 할 수 있을 거라고 예상. 현재는 '지보'라는 로봇이 인간한테 들은 말이 긍정적이면 좋게, 부정적이면 상심하는 태도를 보임.
- 머신러닝(Machine Learning, 기계 학습) : 인공지능을 구현하기 위한 하나의 분야. 컴퓨터는 이를 통해 많은 데이터를 스스로 학습하여 그 데이터에 대한 패턴 파악 가능. ex) 수신한 메일이 스팸인지 아닌지 구분, 어린애 사진을 보고 피사체가 어린이라는 걸 알아내기
2. 알고리즘 기초
- 알고리즘 : 컴퓨터에 입력한 자료를 출력형태로 만들기 위한 컴퓨터의 처리과정. 명령어들의 순서상 처리. 입력값을 출력값으로 바꾸기 위해 어떤 명령들이 수행돼야 하는지에 대한 규칙들의 순서적 나열.
- 좋은 알고리즘은 정확성, 효율성을 갖춤. 일어날 수 있는 모든 가능성을 예상해야 하고, 가능하면 적은 시간과 노력을 들여야 함.
- 알고리즘을 표현하는 방법 : 자연어(natural language), 의사 코드, 순서도(flowchart) 든.
- 의사코드(pseudocode) : 알고리즘이나 컴퓨터 프로그램을 프로그래밍 언어를 쓰지 않고 표현하는 방법. 즉, 사람한테 익숙한 언어로 표현. 프로그래밍 언어보다 문법적 제약을 적게 받으므로 알고리즘 표현에 많이 사용됨.
- 할당 = 초기화.
- 들여쓰기 = 들여쓰지 않은 윗 문장이 실행될 때까지 반복할 내용.
- 주어진 배열을 탐색하는 알고리즘
- 분할 정복 : 모든 데이터를 다 보지 않고 (전화번호부에서 mike를 찾기 위해 절반씩 찢어 버리듯이) 절반을 그리고 그 절반을 보는 방식. 탐색시간이 굉장히 짧음.
- 선형 탐색 : 탐색 알고리즘의 가장 기본. 원하는 워노가 발견될 때까지 처음부터 마지막 자료까지 차례대로 탐색. 원하는 자료를 찾을 때까지 모든 자료를 확인해야 함. 자료가 정확하지 않거나 그 어떤 정보도 없어서 하나씩 찾아야 하는 경우에 유용함. 이럴 땐 무작위보다 순서대로 찾는 게 낫기 때문. 그래서 정확하지만 아주 비효율적.
- 이진 탐색 : 자료를 절반으로 나눈 후 찾는 값이 어느 쪽에 있는지 파악해 탐색의 범위를 반으로 줄여나가는 탐색 알고리즘. 자료를 절반으로 나누어 탐색시간이 반씩 줄어들기 때문에 선형탐색보다 빠르지만(=탐색 속도가 짧지만) 배열을 정리하는 시간이 추가됨. (그래서 때로는 선형탐색이 더 빠르게 ‘보일’ 수 있음.) 정렬 알고리즘들은 이진 탐색을 구현하는 데 유용함. 이진 탐색의 기본이 정렬된 배열을 만들 수 있다는데 가정을 두기 때문임. 의사 코드를 수행하면, 찾고자 하는 값이 최소값보다 작거나 최대값보다 크면 해당 원소가 배열 안에 없는 걸 알 수 있음.
- 보통 배열이 정렬돼있으면 정렬되지 않은 것보다 더 쉽게 탐색 가능.
- 정렬 알고리즘 = 정렬을 위한 알고리즘.
- 정렬 알고리즘의 효율성을 높이려면?
- 시간 복잡도 : 알고리즘을 수행할 때 걸리는 시간을 기준으로 효율성을 분석하는 것. 연산자의 처리 횟수가 적으면 시간 복잡도가 낮고, 효율성이 높아짐.
- log n < n < n^2
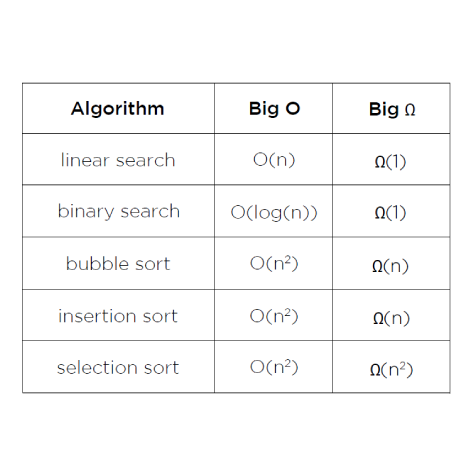
- Big-O 표기법 : ‘대략’을 나타내는 공식적 개념. 최악의 경우에 대한 시간 복잡도를 나타내는 표현. 입력값에 떠라 알고리즘이 점점 커지는 ‘점근적 표기법’. 시간이 많이 걸리는 상한.
ex) 선형 탐색:O(n), 버블 정렬:O(n^2), 선택 정렬:O(n^2), 삽입 정렬:O(n^2), 합병 정렬:O(n log n) - Big Ω(omega) 표기법 : 최선의 경우. 즉, 시간 적게 걸리는 하한.
ex) 선형 탐색: Ω(1), 버블 정렬: Ω(n), 선택 정렬: Ω(n^2), 삽입 정렬: Ω(n) - Θ(n) : 같은 알고리즘 내에서 상한인 Big-O와 하한인 오메가의 괄호 안의 값이 서로 같은 경우. Θ는 세타라고 읽음.
- 버블 정렬 : 두 개의 인접한 자료값을 비교하면서 위치를 교환하는 방식으로 정렬. 단 두 개의 요소만 정렬해주는 좁은 범위의 정렬에 집중함. 그래서 간단하지만 시간 낭비가 너무 많이 발생할 수 있음. n개의 요소를 정렬하려면 n-1번 실행해야 함.
- 선택 정렬 : 배열 안의 가장 작은 수(혹은 가장 큰 수)를 찾아 첫 번째 위치(혹은 가장 마지막 위치)의 수와 교환해주는 방식의 정렬. n-1번 교환하고 n^2번 비교함. 교환횟수를 최소화하는 반면에 각 자료를 비교하는 횟수가 증가한 것. 최선의 경우에도 최악의 경우에서 수행하는 횟수만큼 비교와 교환을 해줘야 함.
- 삽입 정렬 : 자료가 정렬된 부분과 정렬되지 않은 부분으로 나누어짐. 정렬되지 않은 부분의 자료가 정렬된 부분의 자리로 삽입되는 형태. 자료를 여러 번 비교하거나 교환할 필요 없음. 자료의 양이 적을 때 성능 우수, 자료 대부분이 이미 정렬 돼있을 때 효율적. 대신 이미 정렬된 자료에 새 자료를 삽입해야 한다면, 정렬된 자료들이 자리를 이동해야 해서 안정성이 낮음.
- 합병 정렬(병합 정렬) : 원소가 한 개가 될 때까지 계속해서 반으로 나누다가(여기까지는 분할정복과 같음) 정렬된 후 다시 합치는 방식. 과정이 재귀적으로 구현됨. 시간이 적게 듦. 즉, 빠름. 하지만 메모리(공간)를 많이 차지하는 단점이 있음.
- 보고 정렬 : 숫자 집합이나 카드 한 벌에서무작위하게 그것을 섞고 정렬됐나 확인하는 것. 정렬될 때까지 반복함. 아주 바보 같은, 비효율적인 방법.
3. 프로그래밍 기초
- IDE(Integrated Development Environment, 통합 개발 환경) : 프로그램 개발시 관련된 모든 작업과정을 하나의 프로그램 안에서 처리하는 환경을 제공하는 소프트웨어.
- 스크래치(Scratch), 엔트리(Entry) : 블록들을 조립하여 프로그램을 만들 수 있는 프로그래밍 언어. MIT미디어랩에서 만듦.
- 스크립트(블록) : 스크래치와 엔트리에서 컴퓨터가 따라야 하는 명령어인 ‘문장(Statement)’을 나타냄. 문장은 알고리즘의 동작 중 하나임.
- 스프라이트(오브젝트) : 스크래치와 엔트리 화면에서 볼 수 있는 캐릭터 같은 객체. 블록들을 이용해 이것에게 말하거나 명령을 내릴 수 있음.
- 컴파일 : 소스 코드를 0과 1로 이루어진 오브젝트 코드로 전환하는 것.
- 변수 : 컴퓨터가 메모리라는 공간에 숫자나 문자 같은 자료를 저장하는 공간. 프로그램 수행에 따라 값이 수정되거나 변경될 수 있음.
- C는 변수를 선언할 때마다 변수의 자료형(Data Type)을 명시해줘야 하는 정적인 형식의 언어. 비교적 최근에 개발된 언어는 프로그램이 실행 시에 변수의 자료형을 유추하는 동적인 형식의 언어
- C의 기본 자료형

- 연산자(Operator)
- 덧셈, 뺄셈, 곱셈 그리고 나눗셈 같은 기본 산술 연산자
- 나눗셈 했을 때 나머지를 구하는 나머지 연산자
- 값을 지정하거나(x=5), 변수의 값을 갱신하는 할당 연산자(+=, -=, *=, /=)
- 변수명 뒤에 ++나 --를 붙여서 변수의 값을 1만큼 증가시키거나 감소시키는 증감 연산자
- 같다는 의미를 갖는 부울 연산자는 ==
- 조건문(Condition) : 특정 코드가 특정 상황에서만 실행되도록 의사 결정하는 코드. 보통 값이 참인지 거짓인지를 나타내는 부울 연산식을 통해 동작.
- if문
- swithch문
- 반복문 : 동일한 코드를 여러 번 반복.
- for문 : 반복을 몇 번 수행해야 하는지 정해져 있을 때 사용.
- while 문 : 특정한 조건을 만족하는 동안 실행. while문의 조건이 항상 참이면 무한반복.
- do-while문 : while문과 다르게 조건에 상관없이 항상 최소 한 번은 실행한 후 조건을 확인.조건이 만족 되면 다시 반복을 하지만 조건이 만족되지 않을 경우에는 반복문을 실행하지 않음.
4. 프로그래밍 응용
- 컴파일(compile) : 소스 코드를 오브젝트 코드로 변환시키는 과정. 전체과정은 네 단계로 나눔.
1. 전처리(Precompile) : # 으로 시작되는 C 소스 코드는 전처리기에게 실질적인 컴파일이 이루어지기 전에 무언가를 실행하라고 알려줌.
2. 컴파일(Compile) : 컴파일러라고 불리는 프로그램은 C 코드를 어셈블리어라는 저수준 프로그래밍 언어로 컴파일함. 컴파일이라는 용어는 소스 코드에서 오브젝트 코드로 변환하는 전체 과정을 통틀어 일컫기도 하지만, 구체적으로 전처리한 소스 코드를 어셈블리 코드로 변환시키는 단계를 말하기도 함.
3. 어셈블(Assemble) : 어셈블리 코드를 오브젝트 코드로 변환. 연속된 0과 1들로 바꿔주는 작업. 소스 코드에서 오브젝트 코드로 컴파일 되어야 할 파일이 딱 한 개라면, 컴파일 작업은 여기서 끝. 그러나 그렇지 않은 경우에는 링크라 불리는 단계가 추가됨.
4. 링크(Link) : 링커는 여러 개의 다른 오브젝트 코드 파일을 실행 가능한 하나의 오브젝트 코드 파일로 합침.
- 소스 코드 : C언어와 같은 프로그래밍 언어로 작성한 코드
- 오브젝트 코드(=기계 코드) : 0과 1로 이루어져 있으며 컴퓨터에게 프로그램이 어떻게 실행되어야 하는지 알려주는 코드
- C에서 make 명령어 자체는 컴파일러가 아니고, clang이라는 컴파일러를 호출해서 C 소스 코드를 오브젝트 코드로 컴파일 하게 함.
- 버그(bug) : 코드에 들어있는 오류
- 디버깅(debugging) : 코드에 있는 버그를 식별하고 고치는 과정. 프로그래머는 디버거라고 불리는 프로그램을 사용하여 디버깅.
- 디버거는 프로그램을 특정 행에서 멈출 수 있게 해주기 때문에 버그 찾기를 도와줌.
- 중지점(breakpoint) : 프로그램이 멈추는 특정 지점.
-GDB : 자주 쓰이는 디버거 중 하나
- C 프로그램에 GDB을 실행시키려면, 먼저 프로그램 컴파일. 그런 다음, 보통 때처럼 ”./프로그램_이름” 을 치지 말고, “gdb 프로그램_이름”.
- GDB가 열리면, 가장 먼저 중지점 설정. 어디에서 프로그램이 잘못되는지 짐작이 간다면, 그 지점 이전에 있는 행에 중지점 설정. 문제가 생길 것이라 생각한 그 지점에 들어서면 어떤 일이 생기는지 볼 수 있기 때문. 어디가 문제인지 확실하지 않다면, 처음부터 모든 코드를 살펴볼 수 있도록 main 함수의 첫 행이 괜찮음.

- 코드의 다음 행으로 나아가고 싶다면 ‘n’ 입력(next). ‘s’(step)를 쳐도 코드의 다음 행으로 가기는 하지만, 함수 내부로 들어가서 함수 내부의 각 행을 훑음.
- 형변환(Typecasting) : 변수를 한 자료형에서 다른 자료형으로 변환하는 것. 정밀도(표현 범위)가 더 높은 자료형으로 바꿀 경우 값에 오차가 발생할 수 있음.
- 명시적 형변환 : 이미 존재하는 변수 앞에 새로운 자료형을 넣어 다른 자료형으로 바꿔주는 것.
- 암묵적 형변환
- 함수 : 특정 목적을 위해 만들어진 재사용 가능한 코드. 입력값과 출력값을 가지며 프로그램 내의 어디에서든 재사용 가능.
- 추상화(abstraction) : 함수를 한번 작성하면 그 함수가 구체적으로 어떻게 만들어졌는지 몰라도 함수를 사용(혹은 호출) 가능.
- 반환 자료형 : 함수를 호출한 쪽에 출력값으로 반환해줄 값의 자료형. 반환할 값이 없을 경우 반환할 값이 비어있다는 의미로 void 사용.
- 매개변수(parameter) : 함수의 괄호 안에 넣는 인자(argument). 함수의 입력값이며 입력값이 없으면 void 사용.
- 범위(Scope)
- 전역변수 : 모든 범위에서 사용.
- 지역변수 : 그 지역 안에서만 사용.
- 배열 : 자료구조 중 일부. 같은 자료형으로 된 여러 개의 변수를 연속적으로 저장.
- 배열의 각 값은 인덱스 숫자로 참조하기 때문에 배열을 반복문으로 돌리기 쉬움.
- 문자열 = 문자배열 : 문자 값을 연속적으로 저장.
- C에서 문자열은 char 값들의 배열을 나타냄.
- C에서 문자열의 마지막 인덱스는 널로 끝나며, ‘\0’으로 표현.
- 널 종단(null-terminator)은 문자열에게 문자열이 끝났고 더 이상의 문자가 남아있지 않다고 말하는 문자.
- 명령줄(Command-line) : 프로그램 실행 가능.
- C에서는 프로그램의 명령행 인자(command-line arguments)들을 명시할 수 있고, 명령줄에 인자들을 명시하여 사용자가 프로그램의 main 함수에 인자들을 전해줄 수 있게 함.
- argc(argument count) : 명령줄에 전달되는 인자의 수. main 함수가 정수형. 정수 하나를 위한 한 덩어리의 메모리. 명령어가 아니며, 단순히 변수의 이름 혹은 인자의 이름을 의미함.
- argv(argument vector) : 인자들 그 자체를 나타내는 배열. main 함수가 문자열 배열. 문자열을 보관하는 한 덩어리의 메모리.
- 세그먼트 : 건드리면 안 되는 한 덩어리의 메모리.
- main 함수 안에서 아무 것도 반환하지 않으면 기본적으로 컴파일러는 자동으로 main 함수가 0을 반환한다고 추정.
- main 함수가 반환하는 값은 종료 코드 : return 0;
- 0이 아닌 종료 코드(보통 1이나 -1)는 일반적으로 프로그램이 실행되는 동안 프로그램이 성공적으로 끝나지 못하게 하는 어떤 오류가 있었다는 것을 의미.
- 입력 유효성 : 사용자가 제공한 입력값이 유효한지 프로그램이 확인하는 것
- ex) 프로그램이 두 개의 명령행 인자를 받는 것으로 알고 있는데, 한 개만 받았다면, 0이 아닌 종료 코드를 반환해 오류를 알림
- 컴퓨터가 argc의 값을 아는 이유는?
- 운영체제 내부에서 제공하는 서비스들 중 하나로, 프로그램을 실행시키면 프로그램은 프롬프트의 본성에 따라서 프롬프트에 입력된 단어들과 프롬프트에 입력된 단어들의 배열을 전달받음. 즉, 운영체제가 main의 인자들을 채워줌.
- 코어 덤프 : 프로그램의 메모리 혹은 RAM 내용의 스냅 사진.
- 라이브러리 : 프로그래머들이 이미 만들어진 코드를 다시 개발하지 않아도 되게 하고, 서로 함께 작업할 수 있도록 만들어주는 함수의 모음.
- C의 라이브러리 사용법 : #include를 사용해 해당 라이브러리의 헤더 파일을 포함해주기.
- C에서 자주 쓰이는 라이브러리 함수
- ctype.h : 문자 분류 함수, 문자열 처리시 문자의 유형에 따라 구분해서 처리해야 하는 경우에 사용
- toupper : 괄호 안에 인자로 어떤 문자를 전달하고 대괄호가 들어간 세련된 기호를 사용해서 배열의 i번째 문자를 '대문자로 변환해서' 전달해줌.
- math.h : 수학 관련 함수, 대부분의 수학 관련 함수는 double형의 인자를 갖고, double형의 값을 리턴
- stdlib.h : 데이터 변환 함수, 데이터 변환 함수는 데이터 간의 형태 변환이 필요할 때 사용
- string.h : 문자열 처리 함수, 하나 혹은 두 개의 문자열을 입력 받아 문자열의 값을 처리
- 캡슐화 : 어떤 개체에 연관되는 정보들을 한 덩어리로 묶음. C에서는 '구조체(structure)'라는 방법 사용.
- 배열은 같은 데이터형의 변수들만 묶을 수 있음.
- 구조체는 서로 다른 자료형의 변수를 하나로 묶어 새로운 자료형을 만들 수 있음. 구조체 안의 정보들은 각각 '멤버'라고 부름. 배열과 다르게 멤버가 몇 개인지 선언하지 않아도 됨. 대신 배열이 인덱스를 사용하여 각 멤버들을 순환하는 것과 달리 구조체는 멤버를 순환할 수 없음.
- 재귀(Recursion) : 함수가 본인 스스로를 호출해서 사용
- 시그마(sigma) : 주어진 수 n 부터 1까지의 연속된 수를 모두 합한 값
- 스택 : 함수가 호출될 때 마다 사용되는 메모리. 재귀 함수에서는 동일한 함수를 계속해서 호출될 때마다 함수를 위한 메모리가 계속해서 할당됨.
- C에는 파일 입출력(File IO) 기능이 있어서 파일에 데이터를 저장하거나 읽어올 수 있음.
- C의 표준 입출력 라이브러리인 stdio.h에서 파일을 읽고 쓰는 기능을 제공.
- 파일의 내용 중에서 한 글자만 읽어오고 싶다면 fgetc 함수, 한 줄을 읽어오고 싶다면 fgets 함수, 정해진 길이만큼의 데이터를 읽어오고 싶다면 fread 함수를 사용. 형식문자열을 사용하여 데이터를 읽어오기 위해서는 fscanf를 이용.
- 파일에 데이터를 한 글자만 쓰고 싶다면 fputc 함수, 한 줄을 쓰고 싶다면 fputs 함수, printf 함수를 사용하면 printf 함수처럼 형식문자열을 이용해 데이터를 쓸 수 있음, fwrite 함수는 배열에 들어있는 데이터를 파일에 쓸 수 있도록 함.
- 파일은 FILE이라고 하는 구조체로 구현 돼있음.
- 파일을 한 번 열면 그 파일은 반드시 닫아야 함. 파일을 계속 열기만하면 파일을 열 수 있는 시스템 리소스가 소진되어 더 이상 파일을 열 수 없게 될 수도 있기 때문.
5. 인터넷과 네트워크
- IP 주소(Internet Protocol Address) :
- 인터넷에 연결된 장치들을 식별할 수 있도록 해주고, 인터넷상의 다른 장치들이 특정 장치를 찾을 수 있도록 해줌.
- IPv4는 #.#.#.# 의 형태. 각 #은 10진수로는 0부터 255까지의 숫자이고 2진수로는 8자리의 숫자. 즉 IP 주소는 32비트로 표현 가능한 약 40억 개의 공인된 주소를 쓸 수 있음.
- IPv6은 #:#:#:#:#:#:#:#의 형태. 콜론으로 구분된 8개의 숫자로 구성됨. 각 숫자를 10진수로 표현하지 않고, 16 bit 숫자를 0000부터 ffff의 16진수로 표현함.
- 인터넷 장치들의 숫자가 폭발적으로 증가할 것을 대비하는 장기적인 대책으로, IPv4라고 불리는 32bit IP 주소 방식을 IPv6라고 불리는 128bit IP 주소 방식으로 대체하도록 함.
- 액세스 포인트(AP) : 무선 장치(노트북이나 휴대폰)를 인터넷에 연결하기 위해서 사용. ex) 무선공유기
- 우리가 인터넷을 사용하는 과정에서 DHCP와 DNS는 특별히 중요한 역할을 담당.
- DHCP(동적 호스트 구성 프로토콜, Dynamic Host Configuration Protocol) : 컴퓨터에 IP 주소를 자동으로 할당
- URL(Uniform Resource Locator) 혹은 도메인 주소 : 웹 페이지에 접속하기 위해 IP주소 대신 텍스트로 된 주소.
- DNS(도메인 이름 시스템, Domain Name System) : URL을 받아서 IP 주소로 변환.
- 인터넷 프로토콜 : 인터넷의 정보들이 어떻게 전송되는지를 정의하기 위한 규칙들.
- IP 주소 : 인터넷 상의 장치들을 식별할 수 있게끔 함.
- IP(인터넷 프로토콜)의 가장 최근 버전은 IPv6로, 기존의 IPv4 프로토콜을 대체하기 위함.
- 사설 IP 주소 : 특정 로컬 네트워크 내에서 사용되도록 따로 떼어놓음. 보통, 사설 IP 주소를 갖는 장치들은 공인 IP 주소를 공유함. 그럼 IPv4 표준에서 필요한 공용 IP 주소의 개수를 줄일 수 있음. 0.#.#.#, 172.16.#.# - 172.31.#.#, 192.168.#.# 의 형태를 같은 주소들은 사설 IP 주소로 쓰기 위해 따로 떼어놓은 것.
- 로컬호스트(localhost) : IP 주소 127.0.0.1은 다른 장치에 연결하는 것이 아니라, 사용자가 현재 사용하고 있는 장치에 연결하는 주소.
- 웹 브라우저에 URL을 치면, 컴퓨터는 DNS 서버에 접속. DNS 서버는 어느 도메인 이름이 어떤 IP 주소와 대응하는지에 대한 정보를 저장하고 있음. DNS 서버는 여러 개. 어느 도메인 이름이 어떤 IP 주소와 대응하는지에 대한 정보가 바뀔 때 모든 DNS 서버들에 들어있는 정보가 같은 시간에 업데이트되지는 않음. 그래서 DNS 시스템의 변경 사항이 인터넷상의 모든 DNS 서버로 전달되는데 시간이 걸리더라도, DNS 서버끼리는 서로 변경된 사항에 대해 공유해야 함.
- DNS에서 관리하는 도메인은 트리 형태의 계층 구조. 기본 최상위 도메인(TLD) 집합은 웹 사이트 주소 마지막 부분(com, net, org, edu 등). 그 앞에 있는 주소들은 서브 도메인이라고 함.
- DNS와 DHCP를 사용하는 과정은 인터넷 프로토콜이 인터넷을 통해 효과적으로 통신하도록 해 주는 중요한 단계들.
- 라우터 : 인터넷의 구성 요소. 데이터를 다양한 네트워크로 보내줌.
- gw : 라우터와 동의어. 게이트웨이의 줄임말.
- 패킷 : 전송되는 데이터들.
- 라우팅 테이블 : 각 데이터 패킷이 목적지 IP 주소에 따라 어디로 보내져야 하는지에 대한 정보 저장. 라우터는 IP 주소의 앞 숫자들을 보고, 패킷을 어느 방향으로 보내야 할지를 판단함.

- TCP(Transmission Control Protocol) : 전송 제어 프로토콜. IP와 함께 쓰이는 또 다른 기술. 패킷이 누락되면 TCP는 컴퓨터에게 누락된 패킷을 가져오라고 지시함. 데이터를 순서 있는 패킷들로 분해하고 각 패킷에 대해서 순서에 맞게 번호를 매김. 패킷 번호 할당 외에도 데이터에 포트 번호를 할당하기도 함.
- TCP는 자주 쓰는 서비스들(ports)에게 고유한 숫자를 부여함.
- FTP(파일 전송 프로토콜) : 21
- SMTP(이메일 전송 프로토콜) : 25
- DNS : 53
- HTTP(브라우저와 서버 사이의 웹 트래픽에 쓰이는 언어) : 80
- HTTPS(HTTP 보안 버전) : 443
- 인터넷 프로토콜(IP) : 정보가 한 컴퓨터에서 다른 컴퓨터로 어떻게 전송되는지에 대한 규칙들을 모아놓은 것. 연결된 라우터들의 망으로 만들어짐.
- 컴퓨터들이 인터넷을 통해 통신하기 위해서는 통신을 어떻게 해야 하는지, 인터넷상의 한 지점에서 다른 지점으로 어떻게 데이터가 도달하는지 알려주는 표준 집합 혹은 프로토콜이 필요. 이러한 프로토콜이 TCP/IP.
- HTTP(Hypertext Transfer Protocol) : 웹 브라우저가 웹 서버와 대화하기 위한 프로토콜.
- 사용자가 웹 페이지를 방문하려 할 때, 그들의 웹 브라우저(클라이언트)는 웹 서버에 웹 페이지의 내용을 요청해야 함.
- 웹 서버는 그 요청에 응답하기 위해 요청을 해석하고, 요청된 페이지를 클라이언트에게 돌려보냄.
- HTTP는 이 과정을 용이하게 해줌.
-특정한 유형의 HTTP 요청
- GET : 단어 GET으로 시작되고 GET 뒤에는 사용자가 요청한 웹 페이지의 경로(URL, Uniform Resource Identifier)를 씀
- POST : 사용자가 온라인 폼에 데이터를 입력하고 웹 서버로 데이터를 전송할 때 사용
- 웹 서버가 클라이언트로부터 HTTP 요청을 받을 때, 서버는 클라이언트로 응답을 돌려보내면서 상태 코드를 함께 보냄.

- 신뢰 모델(Trust Model) : 소프트웨어에 악성 코드가 없다는 커다란 신뢰
- 백도어(Back Door) : . 사용자들이 원래 시스템에 접속하는 방법과는 다른 비정상적인 수단으로 시스템에 접속하는 방법
- 컴파일러 내부의 익스플로잇(Exploit) : 프로그램을 다운로드하기 전에 프로그램의 코드를 볼 수 있고, 그 코드에 악성 코드나 백도어가 없어 보인다고 해도 프로그램 자체가 안전한 것은 아님. 소스 코드를 오브젝트 코드로 변환시키는 프로그램인 컴파일러가 익스플로잇(exploit)의 원천일 가능성 있음. 컴파일러의 소스 파일과 로그인 프로그램의 소스 파일이 악성코드나 백도어를 포함하지 않을 지라도, 소스 파일을 컴파일 하는 과정에서 악성 코드가 주입될 수 있음.
- 사이버 공격 : 해커가 악의적인 목적으로 컴퓨터 시스템과 네트워크를 대상으로 공격을 시도하는 것
- 사이버 보안 : 은 시스템과 관련 있는데 웹사이트와 사용자가 사이버 위협에 스스로 더 잘 대처할 수 있도록 하는 것
- 피싱 공격(phishing) : 해커가 회사를 사칭하는 메일을 보내고 링크로 접속하는 것을 유도하여 사용자의 비밀번호와 민감한 정보를 요청
- 이중 인증 : 비밀번호 도용 방지 수단. 로그인하기 위해 사용자 아이디와 비밀번호를 사용하는 것은 물론 다른 정보도 필요로 함. ex) 사이트에서 여러분 휴대폰에 인증코드를 보내 로그인할 때 입력하게 함.
- HTTPS(HTTP Secure) : HTTP와 보안 소켓 계층(SSL)이라고 불리는 기술을 결합한 인터넷 통신 프로토콜. SSL을 사용하는 웹사이트는 각각 인증서를 갖고 있는데 이것은 웹사이트에 접근하려는 사용자에게 제공됨. 인증서는 웹 브라우저에게 웹 서버로 보내진 요청을 어떻게 암호화했는지 말해주는 공개키를 포함. 웹 서버는 암호화된 요청을 해독하는 다른 키인 비밀키를 갖고 있음.
- 중간자 공격 : 웹 서버와 사용자 사이에 DNS 서버와 라우터 등으로 악성 코드를 보내 https://를 http://로 바꿈.
- 세션 하이재킹 : 쿠키를 얻기 위해 상대방의 네트워크 트래픽을 관찰하고, 상대방의 HTTP 헤더에 쿠키를 사용하여 상대방을 다른 사람으로 생각하도록 웹 서버를 속이는 기술
6. 웹 프로그래밍
- HTML(Hyper Text Markup Language) : 웹 페이지의 내용을 나타내는 언어
- 사용자가 웹 페이지를 요청하면 웹 서버는 페이지의 내용을 HTML로 보내고, 웹 브라우저는 HTML을 해석해 페이지를 사용자에게 보여줌.
- DOM(Document Object Model) : HTML 문서를 트리 계층 구조로 보여주는 모델. html 요소가 트리의 가장 위고, head와 body 태그들로 가지가 뻗어 나가고, head 태그에서는 title 태그로 가지가 뻗어 나감.
- Apache : 웹 서버 소프트웨어
- MySQL : 데이터베이스 서버
- HTML : 웹 페이지의 구조를 표현하기 위한 언어
- CSS(Cascading Style Sheets) : 웹 페이지를 디자인하기 위해 인터넷에서 사용되는 언어.
- HTML의 요소 태그 안에 style 속성으로 사용할 수 있음.
- CSS는 style 태그의 내부에 위치할 수 있고, 이는 대개 HTML 문서의 head 부분에 위치. 이런 방식을 사용하면 같은 HTML 요소를 여러 번 사용하였을 때, 동일한 CSS를 반복할 필요가 없음.
- <style> 태그 안의 내용을 문서로 저장하면, d일반적으로 .css 형태의 파일이 생성. 이런 파일을 head 요소에 <link> 태그를 포함했을 때 CSS가 적용. CSS를 분리된 문서로 만드는 것은 서로 다른 HTML 문서들이 같은 스타일을 사용할 때 유용
- 웹페이지를 디자인하기 위해 CSS로 스타일을 지정하는 방법은 총 ( 3 )가지
- PHP : 웹 페이지에게 어떠한 기능을 주기 위한 해석형 언어. 해석형 언어는 컴파일되지 않고 한 줄씩 인터프리터에 의해 실행.
- main함수가 존재하지 않고, 변수의 자료형을 가지지 않음.
- 배열을 [ ]기호를 이용해 생성.
- 반복문 foreach 문법ㅇ c와 약간 다름.
- 연관배열[결합배열]이 존재해서 해시테이블을 만들 수 있음. $배열명[속성] = [ 값 ];

- SQL(Structured Query Language) : 데이터베이스에서 사용하는 언어. 시퀄 또는 에스큐엘이라고 읽음.
- 데이터베이스 : 데이터를 저장하고 질의할 수 있는 구조. 사용자 데이터를 영구히 저장했다가 필요할 때 가져옴으로써 웹에서 더 좋은 사용자 경험을 제공할 때 사용.
- SQL 언어의 종류는 크게 데이터 조작언어 4개.

- MySQL : 많이 사용되는 데이터베이스 중의 하나. phpMyAdmin과 상호작용하는 웹 기반 툴.
- redirect : 사용자를 다른 URL로 보내게 해주는 함수
- render : 템플릿 생성
- JavaScript :
- 웹 브라우저와 같은 클라이언트에서 사용.
- 사용자가 입력한 데이터를 다루거나 웹 서버에 요청하거나 웹 페이지를 변경하는 역할을 함으로써 사용자가 웹 서비스를 더 잘 사용할 수 있도록 함.
- main 함수 없음.
- 파일되지 않는 해석형 언어.
- 서버에 저장되지만 브라우저가 코드를 내려 받아 사용자의 컴퓨터에서 실행함.
- 큰따옴표와 작은 따옴표 구분이 없음.
